
Piki's Play
chapter 17. UFS1, UFS2 데이터 구조 본문
- 이번장에서는 UFS1, UFS2 파일시스템을 구성하는 데이터 구조체를 설명한다. 데이터 구조체 레이아웃과 해당 구조체들이 파일시스템 이미지에서 어디에 위치하는지 예를들어 설명하겠다.
- 이전 장에서 언급한것 처럼 UFS 데이터 구조체는 다른 형식으로 값들을 저장하기 위해 여러 필드들을 포함하고있다. 예를들어 블록크기를 저장하기 위해 조각 개수와 바이트 개수 둘다 저장한다. 이렇게 다른 형식들을 제공하는 것은 운영체제가 매번 다른 값들을 계산하는 번거로움을 피하기 위해서이다. 어떤 운영체제는 오직 바이트 기반으로 블록크기를 결정하고, 다른 것들은 조각 크기로 블록크기를 결정할 수 있다. 이 장에서는 여러 형식들 중 하나만 확인하겠지만, 그 형식이 모든 도구나 운영체제들에서 적용될지는 장담할 수 없다.
17.1 UFS1 슈퍼블록
- 슈퍼블록은 UFS 파일시스템 범주의 기본 데이터를 포함한다. 데이터 구조체는 UFS1과 UFS2가 다르다. UFS1 슈퍼블록은 섹터 16에 위치하고, 2048바이트지만 대부분이 필수적이지 않으며 그것들은 0이다.
- 앞으로 필수적인 데이터만 언급하겠지만 아래 표는 부가적인 값들이 얼마나 많은지 보여주기 위해 모든 필드를 포함시켰다. FreeBSD, NetBSD, OpenBSD에서 사용되는 UFS1 슈퍼블록 필드들은 아래 표에서 볼 수 있다.




- 첫 필드들은 각 실린더 그룹 내에서 데이터 구조체가 위치하는 오프셋들이다. 또한 각 실린더 그룹에 기준 주소를 계산하기 위해 사용되는 델타와 실린더 값을 볼 수 있다. 그리고 블록, 조각, 실린더 그룹의 전체 개수가 다양한 형식으로 주어진다. 한 실린더 그룹의 inode와 조각 수는 슈퍼블록 마지막 부분에서 주어진다.
- 바이트 128은 블록 할당 최적화 기술을 위한 필드이다. 만약 0이면 운영체제는 새로운 블록을 할당할 때 시간을 절약한다. 이것은 파일시스템에 데이터가 채워질 때 버려지는 공간이 생기고, 단편화가 발생할 수 있다. 만약 1이면 운영체제는 새로운 블록을 할당할 때 공간을 절약하고 공간을 할당할 때 이상적인 크기의 위치를 찾는다. 대신 파일을 생성할 때 많은 시간이 소비될 수 있다. 이것들을 알아두면 파일을 복수할 때 도움이 될 수 있다.
- 바이트 208에서 시작하는 여러 플래그들이 있다. 첫 플래그는 슈퍼블록이 수정될 때 설정되고, 마운트할 때 제거된다. 파일 시스템을 읽기전용으로 마운트할 때 바이트 210 플래그는 1로 설정된다.
※ 마지막으로 바이트 211은 전체적인 플래그이며, 아래에서 주어진 값 중 하나를 포함한다.


- 바이트 1234~1237은 파일 메타 데이터를 저장하는데 사용하는 inode타입이 어떤 것인지 식별하는 필드이다. 필드가 2이면 4.4 BSD inode이고, 0xffffffff라면 4.2 BSD inode이다. 슈퍼블록의 다른 데이터는 부가적이며 대부분 0으로 설정되어있다.
※ 아래 OpenBSD 시스템 이미지를 분석하면 슈퍼블록은 섹터 16에 있고, 4개의 섹터가 할당되어 있는 것을 볼 수 있다.


- 이 파일시스템은 IA32 시스템으로 바이트들이 리틀 엔디안 순서로 저장된다. 스팍 시스템의 파일시스템이라면 빅 엔디안 시스템이고, 각 숫자 필드들에 바이트들을 변환할 필요가 없다.
- 바이트 8~11은 백업 슈퍼 블록이 각 실린더 그룹 기준에서 16조각(0x10) 오프셋에 위치한다는 것을 보여준다. 바이트 12~15는 그룹 기술자가 기준에서 24조각(0x18)의 오프셋에 위치하고 있다는 것을 보여주고, 바이트 16~19는 inode 테이블이 그 기준에서 32조각(0x20) 떨어진 곳에서 시작한다는 것을 확인할 수 있다.
- 바이트 24~27은 UFS1실린더 그룹의 기준을 계산하기 위해서 그 델타 값이 32(0x20)라는 것을 확인할 수 있다. 이것은 그룹0은 조각 0이 기준이고, 그룹1은 조각 32가 기준이라는 것을 의미한다. 슈퍼블록에 바이트 28~31은 원형마스크가 0xfffffff0임을 보여주고, 이것은 그룹 번호의 마지막 4개의 비트만 다루겠다는 것을 의미한다. 그래서 매 16번째 그룹마다 시작으로 돌아와서 기준 오프셋은 조각 0이된다. 위의 경우 그룹 15는 조각 480의 기준 오프셋을 갖고, 그룹 16은 조각 0이 기준 오프셋이 된다.
- 바이트 32~35는 이것이 마지막으로 써진 시간이고, 그 형식은 GMT 1970년 1월 1일 이후로부터의 초 값이다. 바이트 36~49는 파일시스템에 10000(0x2710) 조각이 있다는 것을 보여주고, 바이트 44~47은 파일시스템에 단지 두 실린더 그룹만 있다는 것을 보여준다. 바이트 48~51에서 각 블록의 크기는 8192바이트(0x2000)라는 것을 볼 수 있다. 조각 크기는 바이트 52~55에 1024(0x0400)이다. 이 두 값을 나눌 필요가 없도록 블록당 조각 수는 바이트 56~59에서 주어지며, 값은 8이다.
- 바이트 104~107은 슈퍼 블록 크기 2048(0x0800)을 담고 있다. 바이트 152~155는 실린더 그룹 요약 영역의 위치가 주어지고, 이 파일시스템의 조각 272에 위치한다. 그 크기는 바이트 156~159에서 주어지고, 1024바이트, 즉 한 조각이라는 것을 알 수 있다. 바이트 184~187은 실린더 그룹당 inode 수이고, 이 파일시스템에는 1920(0x0780)개가 있다. 실린더 그룹 당 조각 수는 바이트 188~191에 있고, 해당 수는 8064(0x1f80)이다.
- 플래그들은 바이트 208에서 시작하며 첫 바이트는 0이다. 이것은 슈퍼블록이 마지막 수정한 이후에 써졌다는 것을 의미한다. 바이트 209는 유연한 의존성을 사용했다는 것을 보여주고, 210-211 플래그는 기본상태이다. 바이트 212는 마지막 마운트 지점의 위치를 나타내고, 이 파일시스템은 /mnt/에 마지막으로 마운트되었다고 할 수 있다. 나머지 필드들은 각자 알아서 분석해보자.
17.2 UFS2 슈퍼 블록
- UFS2 슈퍼블록은 UFS1 버전과 동일한 기본 정보를 저장하지만 사용하지 않는 필드들을 제거해서 더 간단하게 했다. UFS1과 같은 필드들이 많지만 32비트이던 필수 필드들을 64비트 버전으로 교체했다. UFS2 슈퍼블록은 전형적으로 섹터 128에 위치하고, 아래 표에서 FreeBSD와 NetBSD에 의해 사용되는 버전의 필드들을 확인할 수 있다.




-> 표에서 있는 필드들이 앞서 보았던 UFS1과 거의 유사하다는 것을 알 수 있다. 관심 있게 볼만한 변경 사항은 마운트 지점이 더 짧아지고, 거기에 볼륨 레이블 필드가 있다는 것이다. 플래그 필드는 1바이트 대신 4바이트로 변경되었지만 위에 표(17.1 플래그 표)에서 주어진 플래그와 동일한 필드들을 사용한다. 또한 UFS1과 UFS2 사이에 구분하는 매직 값이 다르다.
※ FreeBSD 5 시스템의 UFS2 파일시스템 내용은 다음과 같다.


-> 바이트 8~11, 12~15 그리고 16~19는 슈퍼블록이 각 실린더 그룹 시작에서 40조각(0x28), 그룹 기술자는 그룹 시작에서 48조각(0x30), inode테이블은 그룹 시작에서 56조각(0x38) 떨어진 위치에 있다는 것을 알 수 있다. 바이트 44~47은 4개의 실린더 그룹이 있다는 것을 보여준다.
-> 바이트 48~51은 블록 크기를 보여주는 데 16384(0x4000) 바이트이며, 바이트 52~55는 각 조각의 크기 2048(0x0800)바이트를 저장하고 있다. 바이트 184~187은 실린더 그룹 당 1280(0x0500) inode가 있고, 바이트 188~191은 그룹당 5048(0x13b8)조각들이 있다는 것을 보여준다. 조각의 전체 크기는 바이트 1080~1087에서 주어지고, 이 파일 시스템은 오직 20160바이트를 갖는다.
※ fsstat를 실행해서 UFS2 이미지를 분석한 결과는 다음과 같다.
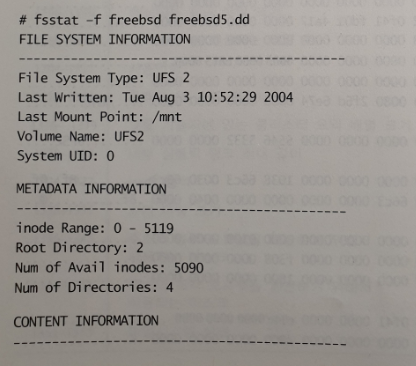

17.3 실린더 그룹 요약
- UFS1, UFS2 둘 다 실린더 그룹 요약 데이터 구조체가 있다. 이 데이터 구조체들은 UFS 두 버전에서 모두 동일하고, 그것들은 각 실린더 그룹에 대한 통계적인 정보를 포함한다. 그것들은 테이블로 구성되며 테이블에 각 엔트리는 실린더 그룹에 해당한다.
※ 그 영역의 주소와 크기는 슈퍼블록에서 주어지며, 각 테이블 필드는 아래 표에 주어진 필드들을 갖는다.

- 다음 절에서 확인하겠지만 이 데이터를 또한 각 실린더 그룹 기술자에서 발견할 수 있으며, 이 정보를 새로운 inode와 블록들을 할당할 때 사용한다.
※ 예제 UFS1 파일시스템 이미지에서 실린더 그룹 요약 영역은 블록 272에 있고, 그 영역에 1024바이트가 할당된다. 그 조각 내용은 다음과 같다.
#dcat -f openbsd openbsd.dd 272 | xxd
0000000 : 0200 0000 2f03 0000 7807 0000 0b00 0000 . . . . / . . . X . . . . . . .
0000016 : 0200 0000 cf00 0000 6d07 0000 0500 0000 . . . . . . . . m . . . . . . .
[REMOVED]
-> 그룹 0의 테이블 엔트리는 첫 번째 줄이고, 거기에 두개의 디렉토리와 815(0x032f)개의 비할당 블록들이 있다. 바이트 8~11은 1912(0x0778)개의 비할당 inode를 저장하고 있고, 바이트 12~15는 일부분의 블록에 11(0x0b)개의 비할당 조각들이 있다는 것을 보여준다. 두 번째 줄은 두 번재 그룹이다.
- TSK fsstat 도구는 UFS 이미지를 분석해서 실린더 그룹의 정보를 보여준다. fsstat 결과는 16장 "파일시스템 범주" 절을 참고하자. 그 결과는 슈퍼블록, 실린더 그룹 요약 영역, 그룹 기술자에서 실린더 그룹 정보를 보여준다.
17.4 UFS1 그룹 기술자
- 그룹 기술자 데이터 구조체는 특정 실린더에 그룹 설정 정보를 담고 있다. 데이터 구조체는 각 실린더 그룹에 위치한다. 기준으로부터의 오프셋은 슈퍼 블록에 저장하고, UFS1과 UFS2는 다른 데이터 구조체를 사용한다. 이 절은 UFS1에서 사용되는 데이터 구조체를 설명한다.
- UFS1 그룹 기술자 위치는 각 실린더 그룹마다 다르지만, 기준 값에서 거리는 항상 일정하다. 기준 계산 방법을 이전 장과 이전 슈퍼블록 절에서 언급했다. 많은 값들이 부가적이고, 이것들은 리소스를 더욱 효육적으로 할당하기 위해 사용된다.
※ UFS1 그룹 기술자에 필드를 아래 표에서 확인할 수 있다.


- 바이트 168에서 시작하는 필드들은 비트맵과 테이블을 포함해 여러 가지 목적을 위해 사용된다. 그룹 기술자는 다양한 비트맵들에 바이트 오프셋을 제공한다. 이 필드들 다음 공간에 여러개의 다른 테이블들과 비트맵들이 있지만 대부분 부가적이다. 그것들은 새로운 블록을 할당할 때 효율성을 위해 존재한다. 예를 들어 블록 비트맵은 조각 비트맵의 축소버전이고, 한 비트는 한 블록에 해당하며, 블록에 해당하는 모든 조각들이 조각 비트맵에서 1을 갖는다면 1로 설정된다.
- OpenBSD UFS1 시스템 첫 번째 그룹에 그룹 기술자를 조사하기 위해서는 그룹 기술자가 어디에 위치하는지를 결정할 필요가 있다. 첫 번째 그룹이므로, 기준 오프셋은 조각 0이다. 그룹 기술자는 기준에서 24조각 위치에 있다는 것을 슈퍼블록에서 확인할 수 있다.
※ dcat을 사용해서 조각 24를 확인해 보았다.

-> 바이트 4~7은 구분 값(magic value)을 저장하고, 바이트 24는 실린더 그룹 요약 영역에서 보았던 이용 가능한 inode수와 블록 수에 대한 정보를 가지고 있다. 또한 그곳에는 할당 정보가 있고, 바이트 40~43은 마지막 블록이 블록 392(0x0188)에 할당됐다는 것을 나타낸다. 바이트 44~47은 마지막 조각이 272(0x0188)에 할당되었다는 것을 보여준다. 마지막 할당된 inode엔트리는 바이트 48~51에 목록이 저장되어 있고, 그 엔트리는 inode 7을 위한것이다. 바이트 92~95는 inode 비트맵의 바이트 오프셋을 담고 있으며, 그룹 기술자 시작에서 264(0x0108)바이트에 위치한다. 조각 비트맵 위치는 바이트 96~99에 있고, 그룹 기술자 시작에서 504(0x01f8)바이트에 위치한다. 블록 비트맵은 바이트 108~111에 있고, 식별자의 시작에서 1540(0x0604)바이트에 위치한다.
17.5 UFS2 그룹 기술자
- UFS2 기술 기술자는 UFS1 버전과 기본 개념은 동일하지만 일부 필드의 크기가 더 크다. 기술자 위치는 슈퍼블록에서 지정되고, 해당 위치는 UFS1 그룹처럼 그룹마다 오프셋이 변하지 않는다. 아래 그림에서 UFS2 버전의 필드들을 확인할 수 있다.


- 두 버전에서 필수적인 정보는 inode와 조각 비트맵 까지의 오프셋이라는 것을 유념하자. 그 비트맵들은 바이트 168 다음에 있지만 여전히 그룹 기술자에 할당된 블록 내부이다.
17.6 블록과 조각 비트맵
- 이 두 비트맵은 블록과 조각의 할당 상태를 결정한다. 사실 UFS에는 블록을 위해 두 비트맵이 있다. 이 비트맵은 '비할당 비트맵' 이며, 그 대상이 할당되지 않을 때 1로 설정되고 할당 될 때는 0으로 설정된다. (이거 헷갈릴 수 있다.)
- 먼저 조각 비트맵을 살펴보면, 각 실린더 그룹은 그룹 기술자 내부에 조각 비트맵을 갖는다. 그 비트맵의 바이트 오프셋은 그룹 기술자에 저장되어 있고, 그 크기는 그룹에 조각 수를 기반으로 결정될 수 있다.
- 특정 조각의 비트를 찾기 위해서는 그룹에 첫 조각의 주소를 빼는 것으로 실린더 그룹의 시작에서 상대적인 주소를 계산할 수 있다. 한 조각이 50번째 그룹에 있다면 그것의 할당 상태는 바이트 6에 두 번째 비트인 50번째 비트에서 주어진다.
- 이전에 분석했던 UFS1 파일시스템에서 그룹 기술자는 블록 24에 위치했으며, 조각 비트맵은 504 바이트 오프셋을 가졌다. 블록의 8개 모든 조각들을 보기 위해 dcat에 8을 지정해서 예제 이미지를 분석해 보도록 하자.

- 바이트 504는 조각 비트맵의 첫 바이트이며, 그 값이 0이라 첫 번째 8개 조각들이 할당되었다는 것을 알 수 있다. 비트맵에서 바이트 34인 바이트 538까지는 어떤 비할당 조각도 볼 수 없다. 276~279의 조각들은 해당 비트맵의 상위 4비트가 1로 설정되어 있어 다음에 이용이 가능하다.
- 이것은 첫 번재 그룹이기 때문에 실제 주소이지만 다른 그룹에서는 그룹의 시작 주소를 더해 줘야 한다. 이 4개의 비할당 조각은 한 개의 블록이 아니기 때문에 블록의 첫 4조각은 할당되고, 마지막 4개는 할당되지 않는다.
- 바이트 548~551은 32개의 연속적인 조각들이 할당되지 않았다는 것을 보여준다. 바이트 548은 비트맵의 바이트 44에 해당하므로 첫 비트는 조각 352를 위한 것이다.
- 조각 비트맵은 블록이나 연속적인 블록의 큰 그룹을 위해서는 효율적이지 못하기 때문에 블록 비트맵이 존재한다. 이 비트맵은 조각 비트맵에서 찾을 수 있는 정보를 복사하지만 각 블록에 1비트를 사용한다. 각 비트는 한 블록에 해당하기 때문에 블록들을 다르게 찾아갈 필요가 있다. 그래서 각 블록을 연속적인 주소에 할당한다.
- 예를 들어 블록당 8개의 조각들을 갖는다면 블록 0, 8, 16, 24 대신 블록 0, 1, 2, 3을 갖는다. 그 블록 주소를 계산하기 위해서는 블록당 조각 수로 조각 기반의 주소를 나눈다. 해당 비트가 1로 설정되면 블록은 이용 가능한 것이다.
※ 다음의 UFS1 시스템 예쩨에서 블록 비트맵이 그룹 기술자 내에 오프셋 1540에 위치한 것을 확인할 수 있다.
# dcat -f openbsd openbsd.dd 24 8 | xxd
[REMOVED]
0001536 : 0100 0000 0000 0000 00f0 0200 0000 0000 . . . . . . . . . . . . . . . .
0001552 : 0000 0000 0000 0000 0000 0000 c0ff ffff . . . . . . . . . . . . . . . .
0001568 : ffff ffff ffff ffff ffff ffff ffff ffff . . . . . . . . . . . . . . . .
[REMOVED]
-> 바이트 1540은 0이고, 바이트 1545까지 상위 4비트가 1로 설정된 것은 없다. 바이트 1545 이것은 비트맵에서 바이트 5이며, 그 비트들은 블록 40~47에 해당되고, 블록 44~47을 위한 비트들은 1로 설정되어 있다.
- 이 주소를 조각 주소로 변환하려면 연속적인 비할당 조각들의 집합처럼 조각 비트맵에서 보았던 조각 352~383을 얻을 수 있다.
17.7 UFS1 inode
- inode 데이터 구조체는 각 파일과 디렉토리의 메타데이터를 저장한다. UFS2에는 다른 필드가 있어 UFS1과 UFS2는 다른 구조체를 사용한다. inode들은 다른 실린더 그룹에 나눠져 있고, 그룹당 inode 수는 슈퍼블록에서 주어진다. 각 실린더 그룹은 슈퍼 블록에서 지정한 위치에 자신들의 inode 테이블을 갖는다.
- UFS1 inode 테이블의 시작 위치는 각 실린더 그룹마다 서로 다른 오프셋을 갖지만, UFS2 inode 테이블은 그룹의 시작에서 항상 동일한 오프셋이다. UFS1 inode 크기는 128바이트이고 아래 표에서 관련 필드들을 확인할 수 있다.

- 모든 필드는 ExtX에서와 같은 값이다. 그 링크는 ExtX에서 보았던 것처럼 같은 목적을 갖고, inode를 가리키는 파일 이름을 위해 증가한다.
- UFS1 이미지에 inode를 보도록 하자. 이장 시작에서는 슈퍼블록은 inode 테이블이 그룹 기준에서 32조각 오프셋을 담고 있다고 설명했었고, 이것은 그룹 0이기 때문에 조각 32에서 테이블이 있다는 것을 알 수 있다. 파일시스템에서 사용 가능한 첫 inode는 3번이며, dcat과 dd로 그 inode를 추출할 수 있다.

-> 첫 4바이트는 모드이고, 15장 "inode" 절에서 이와 유사한 한 개를 분석했기 때문에 이 장에서는 그 과정을 넘어가도록 하겠다. 비트 12~15에 있는 값이 8이므로 정규파일이라는 것을 알 수 있다. 바이트 8~15는 크기이고, 1274800(0x00137400)이다. 바이트 16~19는 A-time이고, 읽을 수 있도록 변환하면 Tue Aug 3 14:12:56 2004 UTC이다. 첫 블록의 주소는 바이트 40~43에 있고, 그것은 288(0x0120)이다. 그래서 두 번째 블록은 296(0x0128)이고, 이것들은 조각 단위이므로 한 블록 차이가 8조각이 난다. 바이트 88~91은 사용 중인 간접 블록 포인트가 있고, 블록 384에 위치한다는 것을 확인할 수 있다. istat 실행 결과는 다음과 같다.

-> 앞의 결과는 할당된 모든 조각 목록을 보여주며 마지막 줄에는 5개의 조각들이 있다.
- inode의 할당상태는 inode 비트맵에 저장되어 있다. inode 비트맵은 실린더 그룹, 그룹 기술자 내부에 위치한다. 아래는 inode테이블이 264바이트 오프셋에서 시작되는 UFS1 그룹 기술자 예이다.
# dcat -f openbsd openbsd.dd 24 8 | xxd
[REMOVED]
0000256 : 3f00 3f00 3f00 3f00 ff00 0000 0000 0000 ? . ? . ? . ? . . . . . . . . . .
0000272 : 0000 0000 0000 0000 0000 0000 0000 0000 . . . . . . . . . . . . . . . . .
[REMOVED]
- 바이트 264는 inode 0~7이 할당되어 0xff로 설정되어 있고 이전에 inode 3은 분석했었다.
inode 8, 그리고 그 이상은 이 실린더 그룹에서 비할당되어 있다.
17.8 UFS2 inodes
- UFS2 inode는 UFS1 inode 보다 더욱 큰 128 바이트이고, 32비트 대신 64비트 필드를 갖는다. inode는 inode 테이블에서 위치를 확인할 수 있는데, 테이블은 슈퍼블록에서 지정되어 있는 오프셋에 위치한다. UFS2 inode 테이블은 일정한 크기의 오프셋을 갖는 것을 제외하면 UFS1과 같다.
※ UFS2 inode 필드는 아래 표에서 확인할 수 있다.


-> UFS1과 UFS2의 차이점이라면 64비트인 블록 포인트와 시간 값이다. 간접 블록에 주소값은 항상 64비트이다.
※ inode 테이블이 조각 56에서 시작하는 것을 UFS2 이미지에서 보았다. inode 5의 예는 다음과 같다.


-> 바이트 0~1은 모드이고, 정규 파일을 나타내는 8이 저장되어있다. 바이트 16~32는 파일 크기가 2097152(0x0020000)라는 것을 보여준다. 바이트 32~39에 8바이트 A-time이 저장되어 있고, 이 값을 Tue Aug 3 15:48:05 2004 UTC로 변환할 수 있다.
- 바이트 112~119는 첫 번째 직접 블록 포인터이고, 블록 232(0xe8)에 있다는 것을 의미한다. 두 번째 블록 포인터는 블록 240(0xf0)이고, 이 이미지의 블록 크기는 블록 당 8개 조각이다. 바이트 208~215는 첫 번째 간접 블록 포인터이고, 블록 328(0x0148)에 할당되어 있는 것을 볼 수 있다.
※ 이 inode에 istat 결과는 다음과 같다.

17.9 UFS2 확장된 속성
- UFS2 파일과 디렉토리에는 사용자나 시스템에 이름과 값 쌍이 할당된 확장된 속성을 갖는다. 확장된 속성들은 일반 데이터 블록에 저장되고, 블록 주소는 inode에서 지정한다.
※ 각 블록은 변동 가능한 길이의 데이터 구조체 목록을 포함하며, 아래 표에서 필드들을 확인할 수 있다.

- 이름의 나머지 부분에 특정 값을 채워 값은 8바이트 경계에서 시작한다. 그 값 또한 특정 값으로 채워 다음 엔트리가 8바이트 경계에서 시작하게 한다. 이름에 채워진 양은 이름 길이를 사용해서 계산할 수 있고, 그 값에 채워진 크기는 바이트 5에서 지정한다.
※ 그 명칭 공간 값은 아래 표에서 주어지는 값 중 한개를 사용한다.

※ 두 속성이 있는 확장된 속성 블록의 내용 예제는 다음과 같다.

-> 바이트 0~3은 레코드 길이가 48(0x30)바이트라는 것을 나타낸다. 바이트 4는 명칭 공간이 1이고, 그것은 사용자 속성임을 의미한다. 위 결과에서 내용에 삽입된 7바이트가 있고, 이름길이는 6바이트라는 것을 볼 수 있고, 그 이름은 'source'이다. 이름은 바이트 12에서 끝나며, 다음 8바이트 경계는 바이트 16이다. 값의 끝 위치를 찾기 위해 레코드 길이와 삽입된 길이에서 시작 바이트를 뺀다. (48-16-7)
17.10 디렉토리 엔트리
- 디렉토리 엔트리 데이터 구조체에서는 파일과 디렉토리 이름을 저장한다. 그 구조체들은 디렉토리에 할당되어 있는 블록에 위치한다. 각 데이터 구조체는 파일 이름과 메타데이터 위치를 확인할 수 있는 inode주소를 포함한다.
※ UFS1과 UFS2 디렉토리 엔트리의 데이터 구조체는 다음과 같다.

※ 파일 타입 플래그는 아래와 같다.

-> ExtX 플래그와 'whiteout' 타입을 제외하면 모두 동일한 이름이다. 그 타입은 파일시스템을 union 옵션으로 마운트해서 같은 이름으로 두 개의 파일을 생성할 수 있도록 한다. 'Whiteout' 타입은 복제 파일에 플래그로 사용되며, 운영체제는 사용자에게 그것을 보여주지 않을 수 있다.
- 디렉토리 엔트리 길이 필드는 다음 할당된 디렉토리 엔트리에 위치를 확인하는 데 사용되며, 그 이름 길이 필드는 그 이름 끝이 어디인지 그 엔트리에 필요한 길이가 얼마인지를 결정하는 데 사용된다. 어떻게 디렉토리 엔트리들이 할당되고 비할당되는지 14장 "파일 이름 범주"를 참조하라.
※ UFS1의 디렉토리 내용을 다음 예제 이미지를 통해서 확인할 수 있다.


-> "ExtX 데이터 구조" 장에서 디렉토리에 대해 자세히 설명했으므로, 여기에는 중요한 몇가지만 보여주겠다. 첫 4바이트 '.' 엔트리의 inode이고, inode 1921(0x0781)라는 것을 확인할 수 있다. 바이트 24~27은 첫 파일 엔트리의 inode 필드로 file1.txt이고, inode 1932(0x078c)이다. 바이트 68~69는 file7.txt 파일의 길이 필드고, 40(0x28)바이트이지만, 그 길이는 오직 9바이트이다. 다음 엔트리 file6.txt는 지워져있으며, file7.txt 파일의 길이 필드는 file6.txt 다음 엔트리를 가리킨다.
※ 예제 OpenBSD 이미지에서 이 디렉토리의 목록은 다음과 같다.

▶ 요약
- 이 장에서는 UFS1과 UFS2 파일시스템과 관련 있는 데이터 구조체를 설명했다. ExtX와 비교해서 이 데이터 구조체들을 대체로 더 크고, 더 많은 부가 데이터를 포함하지만, 그 데이터들은 파일시스템 동작을 효율적으로 만든다.
p.s Fin.
'파일시스템 포렌식 분석'이라는 책을 너무 오랫동안 본 거 같은데 끝을 내서 뭔가 뿌듯..
앞으로 다른 시험 준비가 있어서 나중에는 실습으로 돌아오겠습니다!
'포렌식 > 파일시스템 (파일시스템 포렌식분석)' 카테고리의 다른 글
| UFS1, UFS2 개념과 분석 - 파일 이름 범주, 큰 그림, 다른 주제 (0) | 2020.04.08 |
|---|---|
| UFS1, UFS2 개념과 분석 - 내용 범주 (0) | 2020.04.03 |
| chapter 16. UFS1, UFS2 개념과 분석 (0) | 2020.04.02 |
| Ext 2, Ext 3 개념과 분석 - 응용프로그램 범주 (0) | 2020.03.30 |
| Ext 2, Ext 3 개념과 분석 - 파일 이름 범주 (0) | 2020.03.26 |



