
Piki's Play
Ext 2, Ext 3 개념과 분석 - 파일 이름 범주 본문
14.5 파일 이름 범주
- 데이터 파일 이름 범주는 각 파일과 디렉토리 이름을 저장하는 데이터 구조체를 포함한다. 이 절에서는 그 데이터가 어디에 저장이되고, 그것들을 어떻게 분석하는지를 설명한다.
▶ 개요
- ExtX에는 파일이나 디렉토리의 이름을 저장하는 다양한 방법이 있는데, 여기서는 3가지 방법을 설명하겠다. 먼저 이름 할당에 사용하는 디렉토리 엔트리에 대해 알아보고 하드링크, 소프트 링크, 해시트리를 설명한다.
▷ 디렉토리 엔트리
- ExtX 디렉토리는 inode에서 특별한 타입 값이 있는 것을 제외하고는 정규 파일과 같다. 디렉토리들은 디렉토리 엔트리 데이터 구조체들의 목록을 포함할 블록들을 할당한다. 디렉토리 엔트리는 파일 이름과 파일의 메타데이터를 어디에서 찾을 수 있는지를 설명하는 간단한 데이터 구조체이다. 디렉토리 크기는 하위파일들에 관련이 없고, 그 디렉토리에 할당된 블록들의 수와 관련이 있다.
- 모든 디렉토리는 자신과 부모를 나타내는 '.'과 '..' 디렉토리들의 엔트리들로 시작한다. 그 다음 디렉토리 내 모든 파일과 하위 디렉토리들을 위한 엔트리이다. 루트 디렉토리는 항상 inode 2에 위치한다.
- 파일이름은 1~255 문자열 길이이므로 디렉토리 엔트리는 동적 길이를 갖는다. 그래서 데이터 구조체는 이름 길이를 식별하는 필드가 있고, 다음 디렉토리 엔트리 위치를 확인할 수 있다. 엔트리 길이는 4의 배수로 반올림 한다. 아래 그림 (A)는 한 디렉토리에 3개의 파일이 있는 예이다. C.txt 파일 이후에 공간은 사용하지 않는다.
- 파일이나 디렉토리가 삭제될 때 운영체제는 삭제된 파일 이전 디렉토리 엔트리의 레코드 길이를 증가하므로써 숨긴다. B.txt파일이 삭제되면 a.txt 포인터는 C.txt를 가리키도록하고 이 과정은 (B)에서 확인이 가능하다. 디렉토리 출력은 B.txt를 건너뛰지만 그 데이터는 여전히 존재한다.

- 새로운 엔트리가 생성될 때 운영체제는 각 엔트리를 조사하고 그 레코드 길이와 이름의 길이를 비교한다. 각 디렉토리 엔트리에는 이름 이외에 8바이트 고정 필드가 있고, 최소 레코드 길이는 이름에 8을 더하고 4의 배수를 반올림해서 결정한다. 맨 아래 엔트리는 블록 마지막을 가리키는 것이 필요하다.

-> 마지막 '..' 엔트리는 블록 마지막을 가리켜야 한다. 따라서 4084의 레코드 길이를 갖지만 사실 12바이트만 필요하다. 새로운 엔트리는 또 다시 블록 마지막을 가리킨다. 이는 아래 표에서 확인할 수 있다.

- 디렉토리 엔트리 구조체에는 두가지 버전이 있다. 구 버전에는 이름, inode 주소, 길이 값이 있다. 이후 업데이트된 버전에는 파일이름 길이에 있는 바이트 중 하나를 이용해서 파일, 디렉토리, 문자 장치 같은 파일 타입을 저장한다.
- 파일시스템 이미지 내의 한 디렉토리를 대상으로 fls를 실행한 결과가 아래에 있다. '*'로 표시는 삭제된 파일을 보여준다.

▷ 링크들과 마운트 포인트들
- ExtX는 사용자들이 파일이나 디렉토리에 여러개의 이름을 정의할 수 있도록 소프트링크들을 제공한다. 하드링크는 같은 파일이나 디렉토리의 추가적인 이름이다. 하드링크가 생성된 후 원본이름인지, 링크이름인지를 구분할 수 없다. 하드링크를 만들기 위해 운영체제는 새로운 디렉토리 엔트리를 할당하고, 원본 inode를 가리키도록 한다. inode 링크 카운트는 새로운 이름을 설명하기 위해 1씩 증가한다. 파일은 모든 하드링크들이 제거될때까지 삭제되지 않는다.
- 디렉토리 엔트리 '.'과 '..'은 자신과 부모 디렉토리의 하드링크들이다. 그래서 그 디렉토리에 링크 카운트는 최소 하위 디렉토리 수에 그를 더하는 것과 같다.
- 소프트링크는 파일이나 디렉토리를 위한 두번째 이름으로 다른 파일시스템에 위치할 수 있다. 운영체제는 특별한 타입인 심볼릭 링크를 이용해 소프트 링크를 생성한다. 그 경로의 길이가 60문자를 넘지 않는다면 목적지 파일이나 전체 경로는 파일에 할당된 블록이나 inode에 저장된다. 다음 장에서 심볼릭 링크를 포함하는 데이터 구조체를 보여준다.
- 아래 그림은 하드링크와 소프트링크 예를 보여준다. A는 file1.txt 파일을 가리키는 하드링크, hardlink.txt 예이다. B는 같은 파일의 소프트링크이고, 하드링크와는 간접의 수준이 다른다. softlink.txt에는 파일의 경로를 포함하는 자신의 inode가 있다. 그림 B에서 두 inode의 링크카운트는 1이다. 실제로 심볼릭 링크는 블록포인터에 /file1.txt를 저장하는데 그 경로 길이가 60문자보다 적기 때문이다.

- 유닉스에서 디렉토리들은 파일과 볼륨 마운트 지점을 저장하는데 사용한다. FS1 파일시스템에 dir1이 있는 경우를 생각해보자. 파일시스템 FS2가 dir1에 마운트 되어있다면 dir1에서 FS2 파일들이 보인다. dir1 디렉토리는 FS1에서 자신들을 가지고 있더라도 FS2에 디렉토리가 마운트 된 후로는 확인할 수 없다.
※ 아래 그림을 보면 A dir1에 3개의 그림파일이 있고, B는 dir1이 볼륨 FS2에 마운트되어 루트 디렉토리에 있는 3개의 파일을 포함하고 있다.
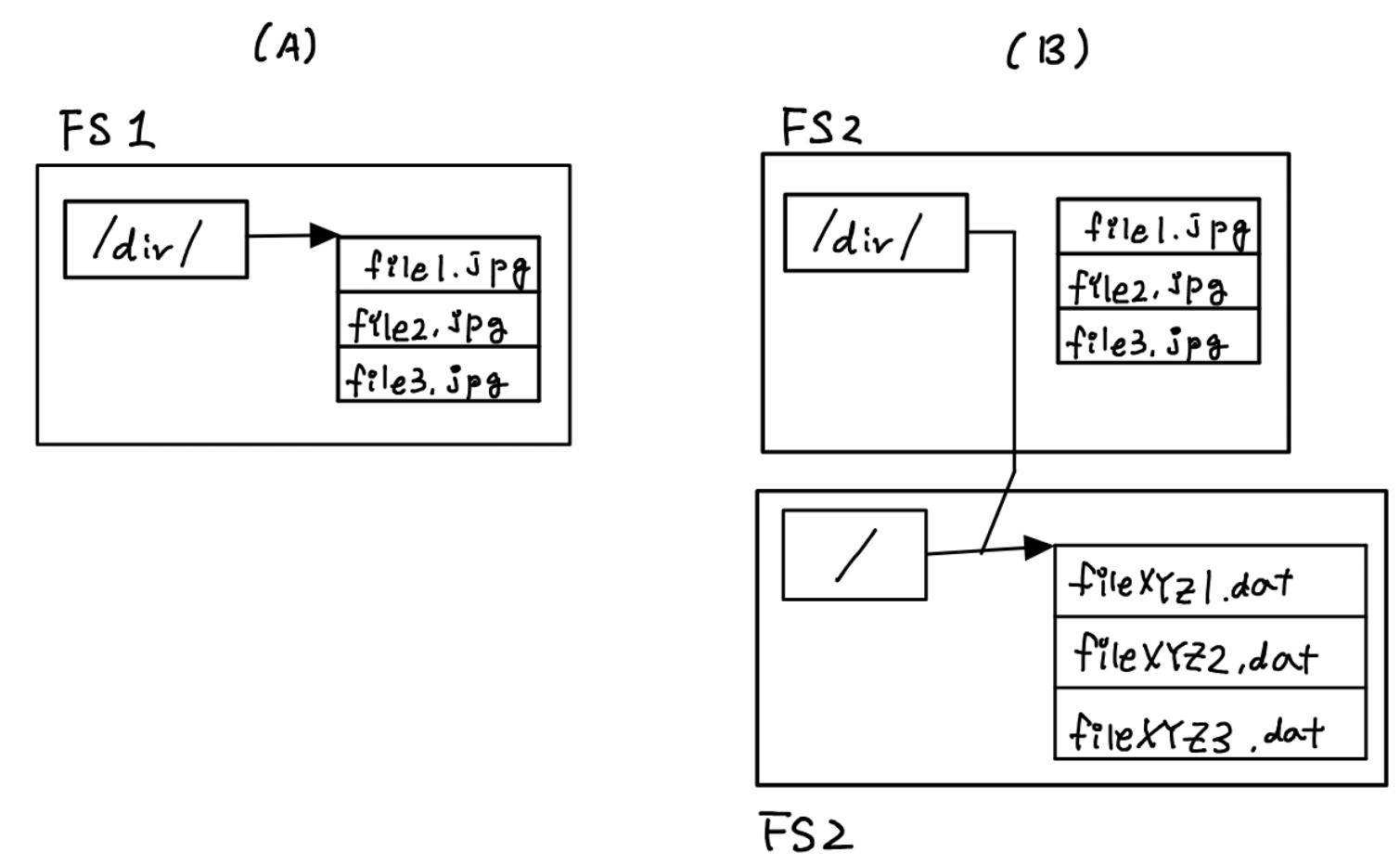
- 수사관에게 이것은 파일시스템들의 마운트 위치를 확인 할 필요가 있다는 것을 의미한다. 어떤 파일을 찾으려면 파일을 찾기 전에 여러 파일시스템을 참고하기 쉽게 배열할 필요가 있다. 왜냐하면 다른 디렉토리들이 다른 볼륨에 있을 수 있기 때문이다. 마운트 되었던 지점에 어느 볼륨이 있었는지 확인해야 한다.
- 한편으로 도구는 마운트 지점의 볼륨을 보여주지 않고, 마운트 지점의 디렉토리 내용을 보여준다. 그래서 파일을 숨기는 방법 중 하나는 디렉토리에 파일을 생성한 후 볼륨을 마운트하면 그 파일을 볼 수 없게된다. (위에 FS1에 파일들을 볼 수 없는 것처럼)
▷ 해시트리
- 파일시스템 생성 시, 사용자는 정렬되지 않은 목록 대신에 파일들을 정리하기 위해 해시트리를 사용하도록 선택 할 수 있다. 해시트리는 여전히 디렉토리 엔트리 데이터 구조체를 사용하지만, 그것들이 정렬된 순서로 있게 된다.
- ExtX 해시트리는 NTFS의 B-Tree와 유사하다. 해시와 B-Tree의 주 차이는 해시는 파일 이름이 아닌 파일이름의 해시를 기반으로 파일들을 정렬한다는것이다.
- 디렉토리가 해시트리를 사용하면 여러개의 블록을 가질 수 있고, 각 블록은 트리에 한 노드가 된다. 각 노드는 파일들을 포함하는데, 파일의 해시값이 주어진 범위내에 있어야 한다. 디렉토리의 첫 블록은 루트노드이고, '.'와 '..' 디렉토리 엔트리를 포함한다. 첫 블록의 나머지에는 해시 값과 블록 주소를 포함하는 노드 기술자가 있다. 운영체제는 주어진 해시 값에서 어떤 블록으로 건너뛰어야 하는지를 결정하기 위해 노드식별자를 사용한다.
- 이러한 내용은 아래 그림에서 볼 수 있다. 첫 블록은 헤더와 노드 기술자를 포함하고 두, 세번째 블록은 파일 디렉토리 엔트리를 포함한다. 해시 트리를 인식하지 못하는 운영체제는 그것들이 정렬된 순서임을 인지하지 못하고, 모든 블록 엔트리를 처리한다. 아래 그림에는 해시 인덱스 트리에 3개의 노드가 있다. 노드 기술자와 실제 디렉토리를 위한 데이터 구조체는 15장에서 확인할 수 있다.

▶ 할당 알고리즘
- 새로운 파일시스템을 생성할 때, 리눅스는 '첫 번째 적용' 할당 정책을 사용한다. 디렉토리의 시작 부분에서 시작하고, 각 디렉토리 엔트리를 조사한다. 이름 길이를 사용하여 엔트리에 필요한 길이가 얼마인지를 계산한다. 그것들의 길이가 다르면 블록 끝이거나, 레코드 길이가 삭제된 엔트리를 덮기 위해서 증가된 것으로 추측할 수 있다.
- 어떤 경우라도 운영체제는 사용하지 않은 영역에 이름을 더한다. 사용하지 않은 영역의 공간이 이름을 위해 충분하다면, 그 이름은 목록에 추가된다. 새로운 블록들은 필요할 때마다 더해지고, 그것들을 사용하기 전에 이전 내용을 영구 삭제한다. 리눅스는 엔트리가 블록 경계를 넘지 못하도록 한다. 다른 운영체제는 다른 정책을 선택 할 수 있다. 해시트리가 사용중이라면 파일은 파일의 해시값에 해당하는 블록에 더해진다.
- 파일이 지워질 때 이전 엔트리 레코드의 길이가 증가되고 다음 엔트리를 가리키도록 한다. Ext3 파일시스템은 디렉토리 크기를 줄이기 위해 사용하지 않은 엔트리들을 다시 배치하지 않는다.
▶ 분석기술
- 파일 이름 범주의 분석은 특정 파일이나 패턴이 있는 파일을 찾을 수 있도록 디렉토리에 있는 이름 목록을 확인하는 것이다. 이 과정의 첫 단계는 항상 inode 2에 위치하는 루트디렉토리 위치를 확인하는 것이다. 디렉토리들은 inode에서 특별한 타입으로 설정되어 있는 것을 제외하면 파일과 거의 유사하다. 할당된 이름만 조사하기 위해 디렉토리 엔트리 구조체를 분석해서 확인된 크기로 이동하고, 다음 엔트리를 분석한다. 이 과정을 블록 마지막이 올 때까지 반복한다.
- 비할당된 파일 이름을 보려면 엔트리에서 확인된 크기는 무시하고, 엔트리 길이를 파악해 그 지점으로 이동한다.
예를들어 마지막 문자가 34바이트 지점이면, 36바이트로 이동한다. (4의 배수를 맞추자) 그 이후 삭제된 엔트리가 있는지 확인하자. 없다면, 4바이트 이상을 이동해서 새로운 지점을 검사해야 한다. 이 과정은 결국 지정한 곳에 이전 디렉토리 엔트리가 있는지 판단하는 것이다.
※ 아래 그림에는 할당된 두 엔트리들 사이에 비할당된 디렉토리 엔트리가 있는지 보여준다. 거기에는 각 디렉토리 엔트리들 사이에 비사용 영역이 있으며, 각 엔트리에서 파일 이름을 못찾으면 앞으로 4바이트씩 나아가자.
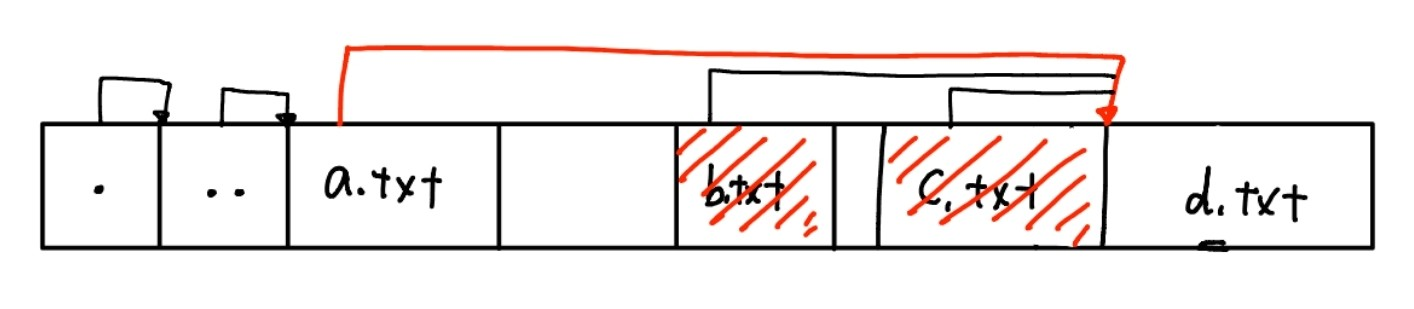
- 디렉토리 엔트리 구조체의 할당 상태는 할당된 엔트리가 구조체를 가리키는 것에 따라 결정된다. 각 디렉토리 첫 두 엔트리는 항상 '.'과 '..' 엔트리들로 할당되어 있다. 관심있는 파일을 찾을 때 inode 주소를 이용해서 메타데이터를 조사할 수 있다.
- 각 블록의 첫 24바이트를 조사해서 '.'과 '..'의 존재여부를 판단하면 디렉토리가 이전에 사용했던 블록을 찾을 수 있다.
- 포인터 값을 이용해서 파일들의 지워진 순서를 추론할 수 있다.
아래 그림은 3개의 연속적인 파일들이 어떻게 삭제 될 수 있는지 6가지의 경우를 보여준다. 맨 위 그림은 4개의 할당된 디렉토리 엔트리들이 있고, 처음 상태이다. 음영처리된 블록은 비할당 된 엔트리이고, 번호는 지워진 순서에 해당한다. 예를들어 A시나리오에서 엔트리 1은 첫번째로 삭제됐고, 엔트리 0의 길이는 결국 3 다음 엔트리를 가리킨다.

- 6가지 시나리오 마지막을 보면 B와 D만 같다. 이 시나리오들 중 두 개는 중간에 있는 파일 마지막에 삭제 됐다고 판단할 수 있다. 다음 시나리오 절에서 이 분석 과정에 대한 예를 보도록하자.
▶ 분석 고려사항
- 삭제된 파일 이름은 ExtX에 그대로 있을 가능성이 크고 리눅스는 Ext3의 inode 번호를 지우지 않기 때문에 그대로 있을 가능성이 크다. 리눅스에서 디렉토리 엔트리 구조체는 새로운 파일 이름의 길이가 같거나, 더 작은 경우 비할당 상태로 남아있다. 그래서 긴 이름의 파일이 짧은 이름의 파일보다 더 빨리 디렉토리 엔트리를 덮어쓴다.
- 다른 운영체제들은 다른 할당 방법을 사용하거나, 심지어 디렉토리 엔트리들을 더 작게 만들기 위해 그것들을 밀집시킨다. 리눅스에서 fsck는 디렉토리들을 더 작게 만들기 위해 디렉토리를 재패키징하고, 비사용 공간을 삭제한다.
- 삭제된 파일 이름을 찾으면 분석을 위해 그 파일을 가져와야 한다. 파일의 inode가 재할당 되었다면 메타데이터는 삭제된 이름과 더 이상 연관이 없을 것이다. 파일이 삭제된 후 inode가 재할당 되었는지 쉽게 알 수 없다. 한가지 방법으로 디렉토리 엔트리에 파일 타입 값과 inode타입을 비교하는 것이다. 만약 디렉토리 엔트리 타입이 디렉토리이고, inode가 정규파일이라면, 그 inode는 재할당 된 것이다. 이것은 TSK fls실행 결과에서 디렉토리 엔트리와 inode 타입을 제공하는 이유이다.
- 디렉토리 엔트리 구조체에 숨겨진 데이터가 있을 수 있다. 마지막 디렉토리 엔트리와 블록 마지막 사이는 사용하지 않는 공간이고, 거기에 데이터가 있을 수 있다. 이것은 해시트리를 사용할 때, 첫 블록에 적은 양의 관리 데이터가 있고, 나머지는 사용하지 않기 때문이다. 하지만 이는 새로운 파일을 생성할 때 운영체제가 덮어쓸 수 있기 때문에 활용하기 쉽지않다.
▶ 분석 시나리오
- ExtX 시스템 분석 시 디렉토리 엔트리를 어떻게 사용하는지 보기위해 이 절에서는 두 가지 시나리오를 보여준다. 먼저 파일의 원본 위치를 확인하고, 다음은 파일이 어떤 순서로 삭제되는지 보자.
▷ 이동한 파일의 원 위치
- 이전에 Snifferlog-1.dat 이름의 파일을 분석했었는데 이번에는 비슷한 이름의 log-001와 유사한 파일 목록을 보자.

-> 이 파일을 생성한 실행 파일을 찾기 위해 전체 경로를 검색했다. 실행파일들은 때때로 자신이 열었던 파일들의 이름을 포함하지만 찾기 힘들 것이다. 위 목록에 수상한 inode 번호가 있다.
- 부모 디렉토리와 다른 파일들은 모두 inode 1840500 근처 주소들을 갖지만, Snifferlog-1.dat 파일은 32579 주소를 갖는다. 파일들은 대체로 부모 디렉토리와 동일한 블록 그룹의 inode를 할당한다. 그래서 Snifferlog-1.dat는 원래 다른 디렉토리에서 할당되었다가 현재 위치로 이동되었거나, 이 디렉토리에 할당되었지만 가용 inode가 없어서 다른 블록 그룹에 할당 되었을 수도 있다.
※ Fsstat을 실행한 결과를 보면 이 로그 디렉토리는 블록그룹 113에 있고, 사용하지 않는 inode가 99%, 비할당 블록이 48%라는 것을 확인할 수 있다. 해서 생성 당시 비할당 inode와 블록은 충분했다는 것을 알 수 있다.

※ 지금부터는 inode가 32579인 Sniffer 로그를 더 상세히 조사한다. 해당 파일은 블록그룹 2에 속해있다.

-> 한가지 가설은 그룹 2에 디렉토리에서 생성 후 113으로 이동했다는 가설이다. 이 경우 Snifferlog-1.dat 실제 부모 디렉토리는 블록그룹 2에 있을 것이다. TSK ils 도구로 이전 부모 디렉토리를 찾을 수 있다. ils는 inode에 범위를 정하면 상세 목록을 만들어 주는데, 블록그룹의 범위를 지정할 수 있고, 모든 비 디렉토리 엔트리들을 필터할 수 있다. -m 플래그는 분석자가 쉽게 읽을 수 있도록 변환하는 기능을 제공하고, -a플래그는 오직 할당된 inode 엔트리들에 대해서만 정보를 제공한다. 또한 grep을 이용해서 디렉토리가 아닌 다른 엔트리들을 필터링한다.

-> 첫 번째 열은 엔트리 할당 상태를 나타내는데 할당되지 않았으면 'dead', 할당됐으면 'alive'로 보여준다.
※ 위 3개의 할당된 디렉토리 중 fls를 이용해 확인할 수 있다. inode 32577의 디렉토리가 가장 가능성이 높아보인다.

-> 이것은 일반적인 mp3 디렉토리처럼 보인다. 이 파일들의 부모 디렉토리는 sniffer로그의 부모 디렉토리 였으므로 inode 할당을 관심있게 보자. sniffer로그의 inode주소는 32579 였고 이는 only_live_twice.mp3와 lic_to_kill.mp3 사이에있다. goldfinger.mp3는 14문자이고 Snifferlog-1.dat는 16문자로서 둘은 동일한 크기의 디렉토리 엔트리를 사용함을 알 수 있다. 타임스탬프를 네트워크 패킷을 이용해 조사한 결과 only_live_twice.mp3 생성후 Snifferlog-1.dat가 생성되었고 이후 lic_to_kill.mp3가 생성되었다 이후 diamonds_forever.mp3, 그리고 이후에 Snifferlog-1.dat는 113그룹 디렉토리로 이동되었다. 그 다음 동일크기 디렉토리 엔트리를 사용하는 goldfinger.mp3가 그 위치에 들어왔다. inode 32577 디렉토리의 M-time과 C-time은 goldfinger.mp3의 파일시간과 같다. (포인터의 변경 때문인 것 같다)
※ 이 관계를 아래 그림에서 볼 수 있다.

-> 이 시나리오에서는 파일의 inode를 이용해서 부모 디렉토리를 추적했다. 그 파일이 같은 블록그룹이나 다른 파일시스템에서 이동 시 그 기술을 활용하지 못했을 것이다.
▷ 파일 삭제 순서
- 리눅스 파일을 조사하는 동안 /usr/local/.oops/ 같은 수상한 디렉토리를 발견했다고 하자. 이 파일들이 어떻게 삭제되었는지 확인하기 위해 아래 표가 필요하고 이 값들을 얻기 위해서 엔트리 분석을 해야한다.

- 위 값들을 이용해서 파일들의 삭제 순서를 분석해보자. Mytools.zip의 레코드 길이가 44이기 때문에 delete-files.sh가 먼저 삭제되었음을 알 수 있다. 만약 Sniffer가 mytools.zip보다 먼저 삭제되었다면 16만큼 레코드 길이가 늘어났을 것이다.
위와 같이 삭제시 Allfiles.tar, config.dat, delete-files.sh의 순서는 알 수 없지만 알파벳 순으로 삭제되었다고 "예상" 할 수 있다. rm* 명령어가 알파벳 순서로 삭제하기 때문이다.
p.s 몸이 안좋아서 자주 못올리네요ㅜㅜ
'포렌식 > 파일시스템 (파일시스템 포렌식분석)' 카테고리의 다른 글
| chapter 16. UFS1, UFS2 개념과 분석 (0) | 2020.04.02 |
|---|---|
| Ext 2, Ext 3 개념과 분석 - 응용프로그램 범주 (0) | 2020.03.30 |
| Ext 2, Ext 3 개념과 분석 - 메타데이터 범주 (0) | 2020.03.20 |
| Ext 2, Ext 3 개념과 분석 - 내용 범주 (0) | 2020.03.19 |
| Chapter 14. Ext 2, Ext 3 개념과 분석 (0) | 2020.03.18 |


