(Part 3) Chapter 8. 파일시스템 분석 - 기초, 파일시스템, 내용
-> 파일시스템 분석은 볼륨의 내부 데이터를 조사하고 파일 시스템을 해석하는 것이다. 궁극적인 목적은 디렉토리에 파일목록을 작성하거나 지워진 파일을 복구, 섹터의 내용을 보기 위함이다.
이번 장에서는 특정 도구를 이용한 파일시스템 분석 방법으로 제한하지 않고 이론적인 방법으로 배우고, 일반적인 용어를 사용한다.
8.1 파일 시스템이란?
-> 컴퓨터들은 데이터를 장기적으로 저장, 그리고 검색 할 수 있도록 구조적 데이터와 사용자 데이터로 구성이 된다. 대부분의 파일시스템은 특정 컴퓨터와 독립적이다. 즉, 파일시스템만의 특징을 가지고있다.
▶ 데이터 분류
-> 여러개의 다른 파일시스템을 조사하고, 기본적인 참조모델을 이용하여 그 타입들을 더 쉽게 비교할 수 있다.
기본적인 모델은 5가지로 분류된다.
파일시스템, 내용, 메타데이터, 파일이름, 응용프로그램
(5가지 범주 중요하다)
-> 파일시스템의 모든 데이터는 위 범주(Category) 중 하나에 포함된다. TSK 도구는 이같은 범주를 기반으로 동작한다.
1. 파일시스템 범주는 전체 파일시스템의 정보를 포함한다. 각 파일시스템의 요소는 일정한 크기를 갖고 성능을 최적화하기 때문에 고유하다. 또한 파일시스템 범주 데이터는 데이터구조 위치, 유닛 크기를 알려준다. 즉, 이런 범주데이터를 특정 파일 시스템을 위한 지도(map)으로 생각할 수 있다.
2. 내용 범주는 파일시스템이 존재하는 첫번재 이유로 파일의 실제 내용을 구성하는 데이터를 포함한다. 파일시스템 대부분의 데이터는 이 범주에 속하고, 일정 크기의 저장소 집합으로 구성된다.
파일시스템은 저장소를 보통 클러스터, 블록 같은 이름으로 부르지만 여기서는 '데이터 유닛(Data Units)' 이라는 용어를 사용하겠다.
3. 메타데이터 범주는 파일을 설명하는 데이터를 포함한다. 즉, '데이터를 위한 데이터'로 볼 수 있다.
그렇기 때문에 저장위치, 크기, 접근 및 수정시간, 접근제어등을 표시하고 파일이름과, 내용은 표시하지 않는다.
예로는 'FAT 디렉토리 엔트리', 'NTFS MFT(Master File Table)', 'UFS', 'EXT3 inode구조'가 있다.
4. 파일 이름 범주는 '파일명'이 할당된 데이터이다. 이 데이터는 보통 '디렉토리 내용'에 위치하고, 해당하는 메타데이터 주소가 있는 파일명의 목록이다. 마치 네트워크 호스트 이름과 비슷하다. (ip가 아닌 사람들이 설정한 이름으로 통신연결을 한다. 내부에서 자체적으로 이름과 ip를 변경한 것 처럼 작동한다.)
5. 응용프로그램 범주는 특별한 기능을 제공하는 데이터를 포함한다. 보통 파일을 읽고 쓰는데는 필요가 없지만 통계나 저널과 같이 특별한 기능에 사용이 된다. 조사할 때 이 데이터는 유용하지만 파일을 읽고 쓸 때는 필요하지 않기 때문에 쉽게 변조가 가능하다.

▶ 필수 데이터와 부가 데이터
- 필수적인 파일시스템 데이터 : 파일을 저장하고 가져오는 데 필요한 것들이다.
ex) 파일 내용, 파일명을 저장하는 주소, 메타데이터 구조에서 이름으로 연결하는 포인터
- 부가적인 파일 시스템 데이터 (Non-essential file system data) : 단지 편리함을 위해 존재하는 데이터
ex) 접근시간과, 허용권
- 필수데이터가 비 신뢰적이면 읽어오는데 문제가 발생하지만 부가데이터가 비 신뢰적이여도 저장하고 가져오는데 문제가 되지 않는다.
=> 운영체제 마다 필수 데이터가 다르기 대문에 파일시스템에 데이터를 썼던 운영체제를 확인하는 것도 중요하다.
ex) 파일 복구시 FAT파일시스템의 파일복구를 묻는 것은 적절하지 않다. FAT 파일시스템에 설치된 xx 운영체제에서 지워진 데이터에 대해 물어봐야 한다.
▶ 분류를 통한 분석
-> 이번 장의 나머지 절에서 파일시스템 분석을 위해 다섯가지 데이터 범주를 설명한다.
1장에서 증거가 가져야하는 속성과 찾을 수 있는 위치를 예상하는 것이 증거를 찾을 수 있다고 했다. 증거를 찾을 수 있는 장소를 기반으로 적절한 데이터 범주와 증거를 검색하는 기술들을 구분할 수 있다.
ex)
JPG 확장자 파일을 찾으면 - 파일이름 범주 분석
특정값으로 파일을 찾으면 - 메타데이터 범주 분석
8.2 파일 시스템 범주
-> 파일시스템 범주는 어떻게 이 파일시스템이 고유한지, 중요한 데이터들이 어디에 위치했는지를 구분하는 전반적인 데이터를 포함한다. 대부분 이러한 데이터는 파일시스템 첫 번째 섹터 표준 데이터 구조체에 저장된다.
- 이 단계에서는 다른 범주의 데이터 구조체 위치를 찾아야하므로 파일시스템 분석의 모든 유형들을 필요로한다. 그래서 이 범주의 특정 데이터를 손실하거나 잃어버리면 추가 분석이 어려울 수 있다.
- 이 범주의 분석은 전반적인 레이아웃 외에 파일시스템의 버전, 응용프로그램, 생성날짜, 레이블 등을 확인하는 것이다.
- 이 범주의 비-레이아웃 데이터를 부가데이터로 간주하고 비 신뢰한다.
▷ 분석 기술
- 이 범주는 다른 범주 데이터들에 비해 보통 독립적이다.
- 데이터를 표시하거나 분석 도구에서 사용하는 것 외에는 활용도가 높지 않다.
- 수사관이 데이터를 직접 복구시 레이아웃 정보를 알아내야 하므로 유용하고, 어떤 컴퓨터에서 파일이 생성되었는지 확인하려 할때 볼륨 ID확인이나, 버전확인하는 것도 유용하다.
- 무결성 검사는 파일시스템이 있는 볼륨크기와 파일시스템 크기를 비교하는 것이다. 이렇게 두개를 비교했을때 볼륨크기가 파일시스템의 크기보다 더 크다면 '볼륨슬렉(Volume slack)'이라는 공간이 생긴 것이고 이 섹터에는 데이터를 숨길 수 있다. (그림은 뒤에 나옴!)
- TSK에는 파일시스템 범주 데이터를 포함하는 fsstat 도구가 있다. -> 다음장에서 보자.
8.3 내용 범주
-> 여기서는 데이터 저장을 위한 '파일'과 디렉토리를 할당하는 저장공간이 존재한다.
데이터는 보통 같은 크기의 그룹들로 구성이 되는데, 각 파일시스템에서는 그것들은 '클러스터', '블록'이라는 이름으로 부른다. 하지만 이 책에서는 '데이터 유닛'이라는 이름을 사용하겠다.
- 데이터 유닛은 '할당', '비할당' 두 가지의 상태를 가진다. 데이터 구조체에는 각 데이터 유닛의 할당 상태를 추적하는 몇개의 타입이 있다.
- 새로운 파일을 생성하거나 이미 존재한 파일에 내용을 추가할 때 비할당 데이터 유닛을 찾고 그 유닛에 데이터를 할당한다.
- 파일이 지워지면 할당한 데이터 유닛을 비할당으로 바꾼다. '영구삭제' 기능이 있어도 OS는 비할당인 데이터 유닛의 내용을 지우지 않는다. (비할당 상태면 패스하는 느낌)
- 내용범주 분석은 지워진 데이터를 복구하고, 낮은 수준 검색을 수행한다.
=> 상당히 많은 데이터가 존재하므로 수동으로 분석이 힘들다.
▶ 전반적인 정보
-> 여기서는 데이터 유닛 주소지정방법, 데이터 유닛 할당방법, 파일시스템이 손상된 데이터 유닛 처리방법에 대해 알아보자!
▷ 논리적 파일 시스템 주소
- 한 섹터는 보는 관점에 따라 여러개의 주소를 가진다. -> 디스크에서 물리적 주소와 볼륨에서의 상대적(논리적) 주소
- 논리적 볼륨주소 내에서 데이터 유닛을 구성하기 위해 그리고 연속적인 섹터를 그룹화 하기위해 논리적 파일시스템 주소도 부여한다.

-> 15개의 섹터가 있는 볼륨과 5개의 데이터 유닛이 있는 파일시스템이 있다. 파일시스템은 논리적 볼륨주소 2개 당 한개의 데이터 유닛을 할당한다. 이 파일시스템은 섹터 4부터 13까지이고 14는 볼륨슬렉(Volume Slack) 이다.
▷ 데이터 유닛 할당 정책
- 운영체제마다 데이터 유닛 할당 정책이 다르다. 대부분 연속적인 데이터 유닛을 할당하지만 아닐때도 있고 이를 '단편화'되었다고 한다.
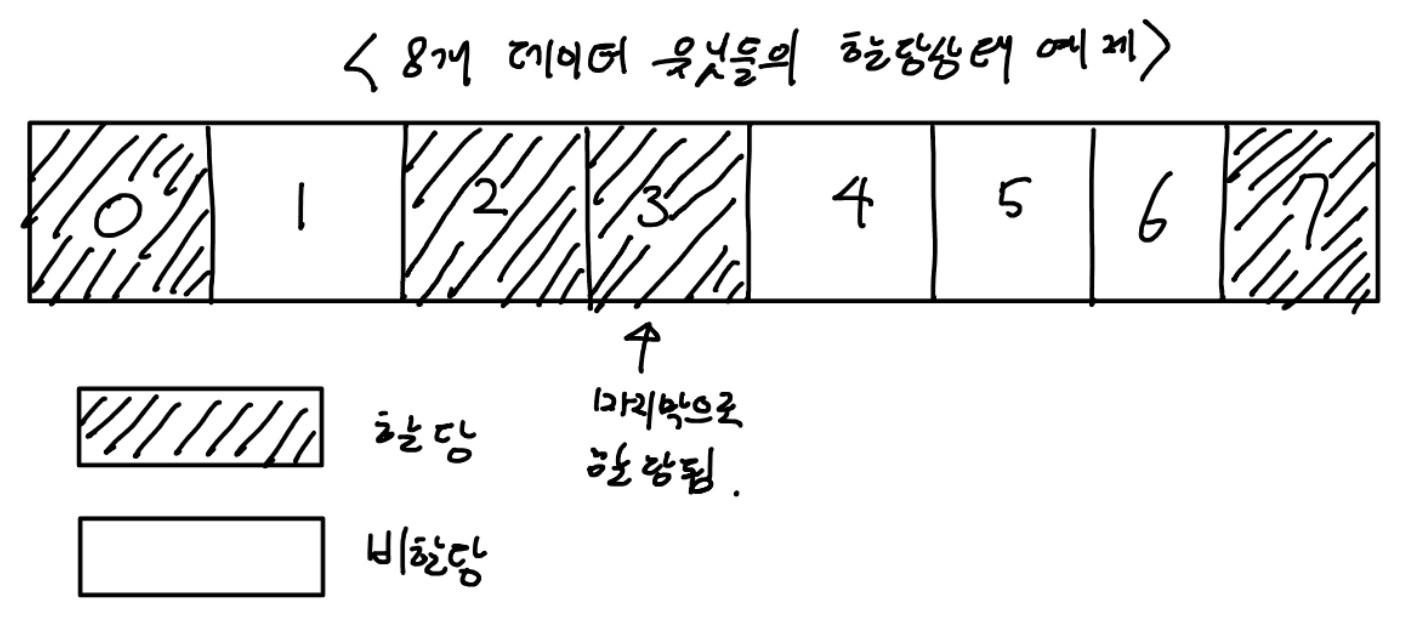
1. '첫 번째 적용(first-available)'은 파일시스템의 첫 데이터 유닛부터 검색하여 사용가능한 데이터 유닛을 찾는 것이다. 항상 처음부터 찾기 때문에 쉽게 단편화가 일어난다.
위 예제에서 첫 번째 적용 방법 이용시 데이터 유닛1에 데이터를 할당할 것이다. 이렇게 할당하다보면 앞부분위주로 데이터가 모이게 되고 상대적으로 뒷부분의 데이터 복구가 쉬워진다. (덮어쓰는 횟수가 적기때문)
2. '다음 적용(Next-Available)'은 마지막 할당 그 이후부터 할당하는 것이다. (위 예제에서는 4번자리) 이 할당 방법은 복구에 좀더 유리한데 파이시스템이 끝까지 재할당 된 후 파일시스템 시작 부분이 다시 재할당 되기 때문이다. 모두 할당되어야 그 다음에 덮어쓰기 때문에 복구가 유리하다.
3. '자동 맞춤(Best-Fit)'은 파일 데이터 크기에 맞는 연속적인 데이터 유닛을 검색하는 것이다.
만약 2개의 데이터 유닛이 필요한 파일의 경우 1, 4를 고르는 대신 연속적인 4, 5를 선택한다.
- 각 운영체제는 파일시스템을 위해 할당정책을 선택할 수 있다. 수사관은 조사전에 파일시스템 구현을 테스트해보고 어떠한 정책을 사용하는 지 알아내야 한다. (물론 명세에 나와있겠지만 무조권적으로 믿으면 안된다.)
- 그러나 위처럼 직접 테스트(운영체제 정책 테스트) 외에도 응용프로그램도 고려해야한다. 응용프로그램이 다른 방법으로 덮어써버릴 수도 있기 때문이다.
▷ 손상된 데이터 유닛
- 많은 파일시스템들은 손상된 데이터 유닛을 표시할 수 있는 기능이 있다. 손상된 데이터 유닛을 표시하고 데이터를 할당하지 않는다. 최근 하드디스크는 스스로 불량섹터를 감지할 수 있고, 교체도 하기 때문에 별도의 표시기능이 필요가 없다. 하지만 이 기능을 악용할 수도 있다. 따라서 수집도구의 불량섹터 보고와 손상된 리스트를 비교해서 더해진 섹터를 찾을 필요가 있다.
▶ 분석 기술들
-> 이제 내용 범주 데이터들을 분석해 보자
▷ 데이터 유닛 보기
-> 특정 파일에 할당했거나, 특별한 의미가 있는 증거의 주소를 알려고 할때 사용하는 기술이다.
- 많은 FAT32 파일시스템에서 섹터3은 사용하지 않는다. 따라서 이 섹터 3의 내용은 0이여야 하는데 0이 아닌 다른 값이 채워져 있다면 이는 용의자가 데이터를 숨겼을 수도 있다.
- 수사관은 데이터 유닛의 논리적 파일시스템 주소에 접근해서 도구를 이용해 바이트나 섹터 주소를 계산한다. (그냥 특정 섹터에 접근을 먼저하고 그곳의 주소를 알아내는 것 같다. 또한 그곳의 내용을 보는 것)
- TSK의 dCat도구는 데이터 유닛을 볼 수 있도록 하고 미가공, 16진수 데이터 평식으로 표현한다.
▷ 논리적 파일시스템 수준 검색
-> 얘는 파일의 내용은 알지만 위치를 모를 때 사용한다. 따라서 특정 문구나 특정 파일 헤더를 일일이 찾아다녀야 한다.
-> 디스크 스패닝이나 RAID에서는 적합하지 않다. 모든 섹터가 물리적 순서로 나열된 '단일디스크'를 조사할 때 효과가 있다. 따라서 '비할당', '할당'공간을 모두 추출해서 비트맵을 만들고, 비할당 공간만을 찾아다니면서 지워진 파일을 복구한다.
- TSK의 dls도구는 파일의 비할당 데이터를 추출하고 dcalc도구는 수사관이 원하는 데이터를 찾은 후 그 데이터가 어떠한 데이터 유닛에 있었는지 알려준다.

▷ 데이터 유닛 할당순서
-> 두개 이상의 데이터 유닛을 할당하는 수서가 중요하다면 할당 정책을 결정하는 운영체제를 조사해보자!
▷ 일관성 검사
-> 일관성 검사는 모든 데이터 범주를 위해 중요한 분석기술이다.
- 내용 범주에 하는 일관성 검사는 '메타데이터'범주의 데이터를 이용하고, 모든 할당된 데이터 유닛이 정확히 하나의 할당된 메타데이터 엔트리 지점을 정확히 갖는지 검증한다.
=> 사용자가 데이터 유닛 할당상태를 직접 설정하는 것을 예방한다.
- 해당하는 메타데이터 엔트리가 없는 데이터 유닛을 '고아 데이터 유닛'이라 부른다.
그림에서 데이터 유닛 2는 '고아 데이터 유닛'이고 데이터 유닛 8은 두 메타 데이터 엔트리를 갖는다. 이는 거의 모든 파일시스템에서 허가되지 않는다.

- 손상된 데이터 유닛은 0을 가지는데 손상된 목록에 있으면서 0을 가지지 않는 데이터 유닛은 '반드시' 조사해야한다.
▶ 영구 삭제 기술
- '영구삭제', '보안삭제' 기술은 파일에 할당된 데이터 유닛과 모든 비할당 데이터 유닛에 '0'이나 난수를 채워둔다.
- 응용프로그램 수준으로 영구삭제를 하기는 힘들다 -> 어자피 운영체제가 0이나 난수를 써야되는데 시간차가 존재하기 때문
- 하지만 이 기술이 사용되면 수사관은 증거를 찾기 힘들다. 그러면 영구삭제 도구를 찾고 언제 접근했는지 알아내고, 복구가 불가능하면 임시파일 복사본이라도 찾아야 한다.
p.s 글이 엄청 많았어가지고 필기정리하는데 오래걸렸던 파트이다ㅜㅜ